در این مطلب یاد میگیریم که چطور با php وب اسکرپینگ انجام دهیم. یعنی از یک صفحه وب اطلاعات مورد نظرمان را استخراج کنیم. به عنوان مثال، یک صفحه از محصولات دیجی کالا انتخاب میکنیم تا عنوان، قیمت و عکس محصول را به دست آوریم.
کاری که در وب اسکرپینگ به طور کلی انجام میدهیم این است که به یک صفحه ریکوئست (request) یا درخواست بفرستیم و تمام اطلاعات صفحه یا همان DOM را دریافت کنیم. بعد محتوای مورد نظرمان را از صفحه استخراج کنیم.
دریافت اطلاعات محصول از دیجی کالا
فرض کنید قرار است از یک صفحه محصول در دیجی کالا اطلاعات محصول را پیدا کنیم. تا بعدا این اطلاعات را به دیتابیس منتقل کنیم یا هر کار دیگری که به آن نیاز داریم.
اول باید آدرس url صفحه مورد نظرمان را مشخص کنیم.
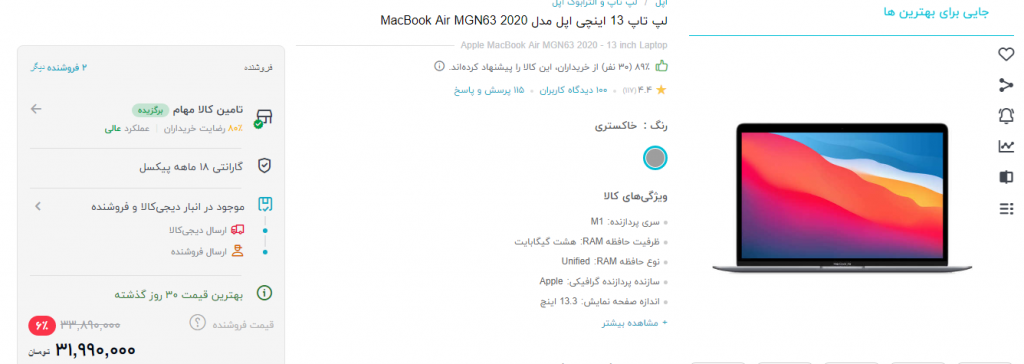
من تصمیم گرفتم برای این مثال، اطلاعات لپتاپ MacBook Air MGN63 را از دیجی کالا با وب اسکرپینگ پیدا کنم.
وب سرور لوکال را اجرا می کنم و یک فایل php درست می کنم به نام scraper.php داخل این فایل تمام کدها را می نویسیم.
من برای اجرای php روی لوکال هاست از لاراگون استفاده میکنم.
آدرس صفحه محصول را در یک متغیر میگذارم به نام $address .
$address="https://www.digikala.com/product/dkp-3735138/%D9%84%D9%BE-%D8%AA%D8%A7%D9%BE-13-%D8%A7%DB%8C%D9%86%DA%86%DB%8C-%D8%A7%D9%BE%D9%84-%D9%85%D8%AF%D9%84-macbook-air-mgn63-2020";یک نگاهی به url بیاندازید، میبینید چون حروف و کلمات فارسی دارد، در ادیتور یا IDE معمولا به شکل کاراکترهای نامفهوم و طولانی ظاهر میشود. البته این هیچ اشکالی برای ما در وب اسکرپینگ ایجاد نمیکند. اما یک راه داریم برای کوتاه url کوتاهتر و تمیزتر شود .
در دیجی کالا هر محصول یک کد دارد که با dkp شروع می شود.اگر یک بررسی کلی کنید می بینید که تمام محصولات دیجی کالا به این فرمت در url آمدهاند.

اگر بعد از کد کالا عنوان فارسی محصول را هم پاک کنیم، همین صفحه باز خواهد شد. همین الان این لینک را هم امتحان کنید تا ببینید.
https://www.digikala.com/product/dkp-3735138
خوب، حالا لینکی که قرار است با آن کار کنیم کوتاهتر و تمیزتر شده.
وب اسرپینگ با استفاده از curl
curl یک کتابخانه یا بهتر بگویم اکستنشن (extension) در php است. معمولا به طور پیشفرض همراه php در وب سرورهایی که از آنها استفاده می کنیم موجود است. با استفاده از curl از طریق کد به یک آدرس url در خواست (request)میفرستیم و پاسخ درخواست (request)را دریافت میکنیم.
مفهوم درخواست یا request در صفحات وب: request یعنی پیغامی است که بین مرورگر و سرور رد و بدل می شود.
همین الان که شما دارید این صفحه را می خوانید با باز کردن این صفحه، مرورگر شما یک request به سرور این وبسایت فرستاده، اطلاعات این صفحه را دریافت کرده و به شما نمایش داده است. curl مشابه همین کار را برای ما در داخل برنامهای که قرار است بنویسیم انجام میدهد.
در فایل scraper.php که ساختیم، این چند خط کد را مینویسیم.
<?php
$address = "https://www.digikala.com/product/dkp-3735138";
$ch = curl_init($address);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
$response = curl_exec($ch);
curl_close($ch);اول از همه url صفحه مورد نظرمان را در متغیر address$ گذاشتم.
curl_init ارسال request به آدرس را شروع می کند.
تابع curl_init یک session جدید ایجاد میکند انگار که یک صفحه مرورگر را با این آدرس باز کرده باشیم. این مقدار را باید در یک متغیر ذخیره کنیم تا در ادامه از آن استفاده کنیم.
تابع curl_setopt تنظیمات request ارسالی را مشخص می کند.
پارامتر اول که همان مقدار به دست آمده از تابع curl_init است.
پارامتر دوم نوع تنظیمات و پارامتر سوم مقدار آن را تعیین می کند. ثابت CURLOPT_RETURNTRANSFER برابر با true، به این معنی است که مقدار پاسخ دریافتی به جای چاپ شدن به صورت یک رشته ذخیره شود.
تنظیمات بیشتری را هم میتوان برای این ریکوئست درنظر گرفت مثل مقدار HEADER ریکوئست یا نوع ارسال ریکوئست(POST،PUT و…). لیست کاملی از این تنظیمات را در این لینک پیدا میکنید.
تابع curl_exec ریکوئست را ارسال می کند و مقدار پاسخ را دریافت میکند. اینجا داخل متغیر $response ذخیره شده.
تابع curl_close سشن (session) curl را بعد از دریافت پاسخ قطع میکند.
دستورات curl باید با curl_init شروع و با curl_close خاتمه یابند.
دریافت پاسخ یا response
مقدار متغیر $response همان پاسخی است که از صفحه مورد نظرمان دریافت کردیم. با دستور echo این مقدار را نمایش دهید:
echo $response;اگر فایل scraper.php را باز کنید نتیجه را خواهید دید.
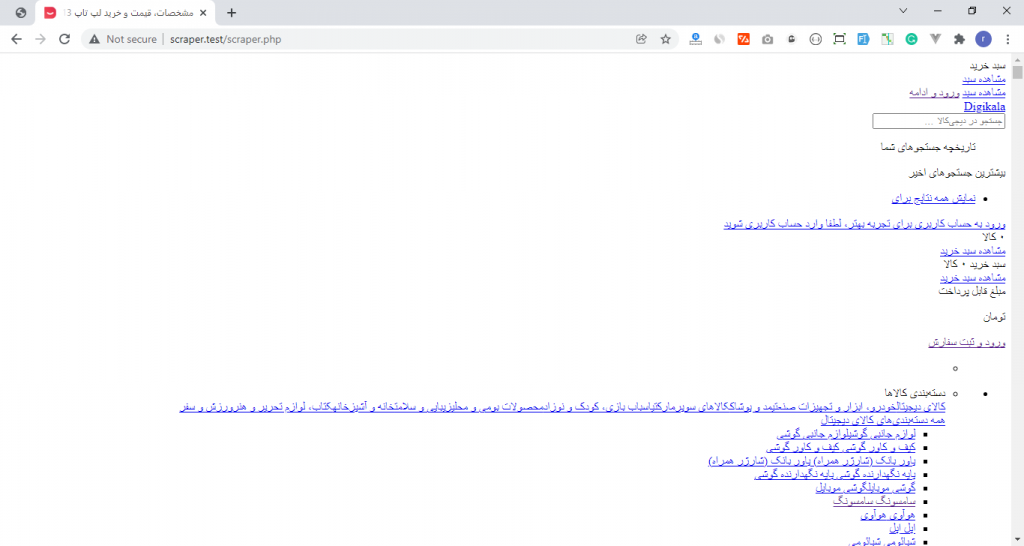
کدهای html صفحه محصول در متغیر response$ ذخیره شده بود و با چاپ این متغیر صفحه محصول به صورت کامل در این صفحه ظاهر شده. البته بدون ظاهر مناسب. چون آدرس فایل های css دیجی کالا به صورت نسبی وارد نوشته شده و باید در دامنه دیجی کالا باشیم تا درست کار کنند.
دریافت اطلاعات مورد نیاز از صفحه با Xpath
حالا که کد html صفحه را به صورت یک رشته در متغیر ذخیره کردیم، باید چیزهایی که نیاز داریم را از آن استخراج کنیم.
همانطورکه از اول قرار بود، قصد ما پیدا کردن سه مقدار است:
- عنوان محصول
- قیمت
- عکس محصول
این کار را با استفاده از XPath انجام می دهیم. XPath یک ابزار برای پیدا کردن و فیلتر کردن اطلاعات از داحل یک فایل xml است.
احتمالا بریتان سوال باشد که تا اینجا ما html را دریافت کردیم. الان چه نیازی به xml داریم؟ اصلا xml چی هست؟
اجازه بدهید خیلی مختصر و مفید ببینیم این xml چیست و چه کار میکند:
تعریف: xml یک زبان نشانه گذاری مشابه HTML است که ساختار مشخصی دارد و برای نمایش اطلاعات یا حتی ذخیره یک سری تنظیمات در نرم افزارهای مختلف استفاده می شود.
آیا نمیشد با همان html ای که دریافت کرده بودیم این کار را انجام بدهیم؟ بله امکان پذیر بود. اما در آن صورت، نیاز به کار با عبارات باقاعده یا regex داشتیم. کار با regex خیلی راحت نیست. به همین خاطر html را به xml تبدیل میکنیم تا با xpath خیلی آسانتر اطلاعات دلخواهمان را پیدا کنیم.
پس یک تابع مینویسیم که html را دریافت کند و به ما xml تحویل دهد.
function create_xpath_object($item){
$xmldom = new DOMDocument();
@$xmldom->LoadHTML($item);
$xml_xpath = new DOMXPath($xmldom);
return $xml_xpath;
}
تابع create_xpath_object را بررسی کنیم:
$xmldom = new DOMDocument();
خط اول یک سند DOM می سازد و آن را در یک متغیر می گذارد.
@$xmldom->LoadHTML($item);خط بعدی صفحه html را داخل این سند قرار میدهد. این کار با متد loadHTML انجام میشود.
اگر دقت کنید قبل از این کد یک علامت @ قرار گرفته. این باعث می شود که از خطاهای html که تقریبا در همه صفحات وب وجود دارد صرف نظر کند. (برای اینکه فرقش را متوجه شوید یک بار بدون @ امتحان کنید)
$xml_xpath = new DOMXPath($xmldom);
return $xml_xpath;
حالا با این سند xml که ساختیم، با کلاس DOMXPath یک شی میسازیم. و درنهایت این شی ساخته شده را return میکنیم.
از این تابع برای ساخت آبجکت XPath از صفحه html استفاده میکنیم:
$xpath_object = create_xpath_object($response);
تا اینجا صفحه html ما تبدیل به آبجکت XPath شده. حالا ببینیم چطور میشود اطلاعاتی که نیاز داشتیم را از صفحه استخراج کنیم.
پیدا کردن عنوان محصول
میدانیم که عنوان صفحه معمولا در تگ h1 وجود دارد. اگر هم نباشد می توانیم بررسی کنیم تا مطمئن شویم.
با استفاده از developer tools یک نگاهی به سورسhtml صفحه بیاندازید. نگاه کنید عنوان محصول دقیقا کجاست.
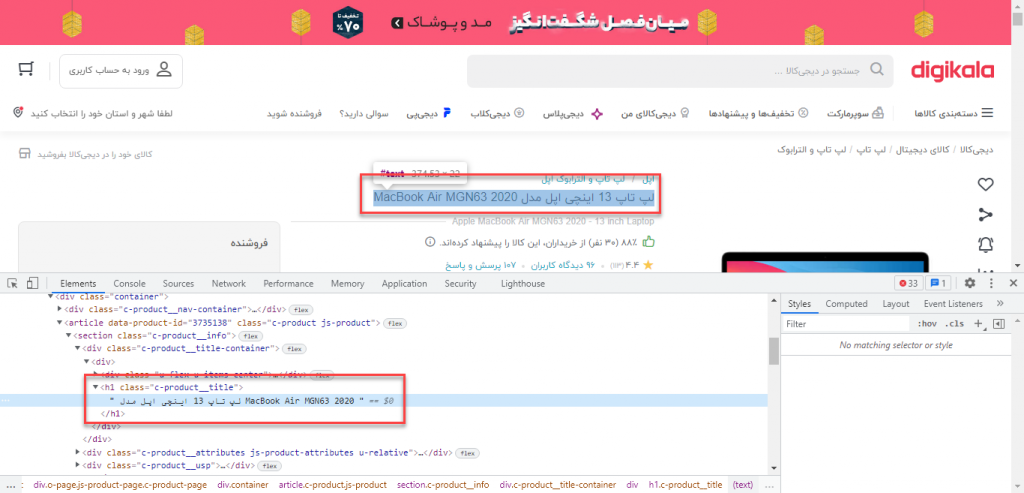
عنوان داخل تگ h1 قرار دارد. پس ما باید مقدار این تگ را دریافت کنیم. آبجکت XPath که ساخته بودیم یک متد دارد به نام query، که با آن تگ html مورد نظرمان را پیدا میکنیم.
$product_title = $xpath_object->query('//h1');
پارامتر داخل متد query، باید به شکل string نوشته شود. دو بک اسلش(//) قبل از اسم تگ به این معنی است که هر چه تگ h1 است را پیدا کن. همه تگها به صورت آرایه داخل متغیر product_title$ قرار میگیرند.
مقداری که از کد بالا دریافت میکنیم به شکل آرایه است، پس باید مشخص کنیم کدام عضو از این آرایه را نیاز داریم. اینجا یک h1 در صفحه بیشتر نداریم پس عضو اول را می گیریم (کل صفحه یک h1 دارد ما هم با همان h1 اولی که عنوان محصول است کار داریم).
echo $product_title->item(0)->nodeValue;item(0) همان اولین عضو آرایه است. متد nodeValue مقداراین عضو را به ما میدهد.
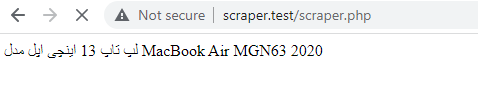
احتمالا اگر به همین شکل این عبارت را چاپ کنید به خاطر فارسی بودن عنوان، با همچین متنی مواجه میشوید.

به کمک تابع utf8_encode کاراکترهای فارسی را به شکل صحیح نشان میدهیم.
echo utf8_encode($product_title->item(0)->nodeValue);
پیدا کردن قیمت محصول
مانند کاری که برای عنوان کردیم، تگ قیمت را با inspect element پیدامی کنیم.
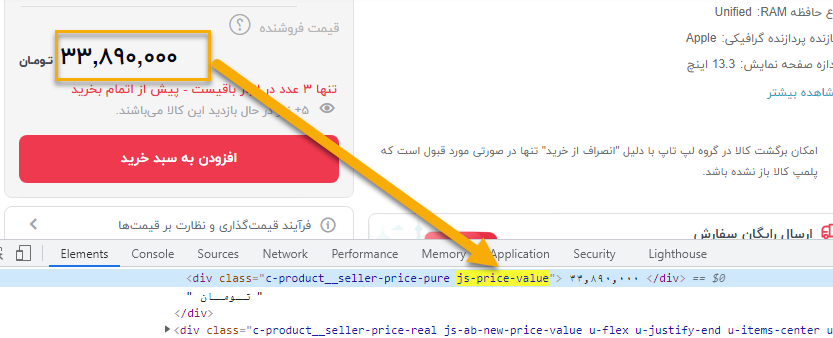
قیمت داخل یک تگ div با کلاس js-price-value نوشته شده.
xpath آن به این شکل نوشته می شود:
$product_price = $xpath_object->query('//div[contains(@class,"js-price-value")]');
شکل xpath اینجا از حالت قبل متفاوت شد. الان دنبال یک تگ با کلاس مشخص می گردیم.
div// که همان تگ div را پیدا میکند.
عبارت [contains(@class,"js-price-value")] یعنی جایی که دارای کلاس js-price-value باشد.
درنهایت این شکلی مقدار قیمت را چاپ می کنیم:
echo utf8_decode($product_price->item(0)->nodeValue);
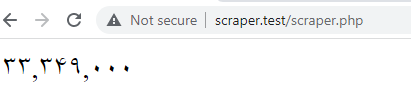
پیدا کردن و دانلود عکس محصول
تا اینجا ما فقط متن دریافت کردیم. اما گاهی اوقات به دریافت عکس هم احتیاج داریم. پس باید عکس را بتوانیم دانلود کنیم، ذخیره کنیم و هرجا نیاز داشتیم استفاده کنیم.
در پایین صفحه، جایی که مشخصات و نقد و بررسی نوشته شده، سمت چپ، عکس محصول به صورت thumbnail قرار گرفته است. روی عکس کلیک راست کنید و inspect را بزنید تا تگی که عکس در آن قرار دارد را پیدا کنید.
عکس داخل تگ img با کلاس c-mini-buy-box__product-info--img قرار دارد.
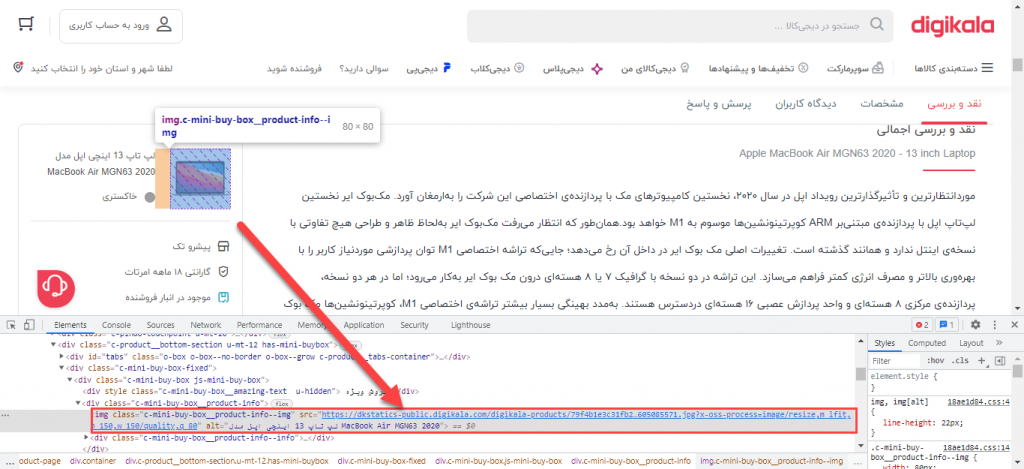
برای دانلود این عکس اولین باید این تگ img را با استفاده از XPath پیدا کنیم.
پس در ادامه کدهای قبلی می نویسیم:
$img = $xpath_object->query('//img[contains(@class,"c-mini-buy-box__product-info--img")]/@src');
$img_url = $img->item(0)->nodeValue;
نوشتن xpath که مثل مثال های قبل است. با // شروع میشود. در ادامه اسم تگ می آید( img).
بعد از آن مشخص می کنیم چه کلاسی دارد.
تا اینجا همه چیز مانند مثال قبل یعنی پیدا کردن قیمت بود. اما چون ما attribute سورس یا همان src تگ را نیاز داریم، بعد از مشخص کردن کلاس باید عبارت@src/ را هم اضافه کنیم.
در آخر هم مقدار src را در متغیر img_url$ میگذاریم.
لینک تصویر را چاپ میکنیم تا ببینیم چیزی که میخواستیم به دست آمده یا خیر.
echo $img_url;
لینک تصویر به درستی دریافت شده. اگر آن را در مرورگر باز کنید می بینید که عکس محصول نمایش داده میشود.
حالا که آدرس را پیدا کردیم، وقت آن است که عکس را دانلود کنیم. انجام این کار هم خیلی سخت نیست.
برای دانلود عکس باید به همین آدرس src که به دست آوردیم به روش قبل یک ریکوئست بفرستیم:
اما قبل از آن نگاهی به آدرس فایل عکس بیاندازید. در آن یک سری کوئری پارامتر(query parameter) دیده میشود. قبل از ریکوئست بهتر است این ها را پاک کنیم. یعنی از علامت سوال به بعد بقیه را حذف کنیم.

برای این کار از یک تابع php به نام strtok استفاده می کنیم:
$img_url_clean = strtok($img_url,'?');
پارامتر اول همان آدرس url است و پارامتر دوم کاراکتری است که رشته باید از آنجا به بعد جدا شود. مقدار نهایی در متغیری به نام image_url_clean$ قرار دادم.
حالا با curl به این آدرس یک ریکوئست میفرستیم:
$ch = curl_init($img_url_clean);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
$image = curl_exec($ch);
$http_response = curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);چون اینجا فایل ما یک عکس است، پاسخ(response) ریکوئست ما هم عکس خواهد بود بر خلاف دو مثال قبلی که متن بود ( صفحه وب در واقع یک فایل متنی است).
پس اینجا من مقدار را در یک متغیر به نام image$ ذخیره کردم. حالا محتوای این متغیر یک عکس است.
چطور این فایلی که دریافت کردیم و در متغیر ذخیره کردیم را دانلود کنیم؟
php دو تابع به نام fopen و fwrite دارد. با fopen یک فایل میسازیم و با fwrite داخل فایل محتوا قرار میدهیم.
$tmp = explode('/',$img_url_clean);
$filename = end($tmp);
$file = fopen($filename,'w+');
fwrite($file,$image);
fclose($file);در دو خط اول کد بالا اسم فایل به همراه پسوند را از url با استفاده از تابع explode به دست آوردم. چون برای ایجاد فایل به این اسم نیاز داریم.
البته هر اسمی میتوانیم روی فایل بگذاریم. اما باید حواسمان باشد که پسوند درست را بنویسیم. وگرنه فایل باز نخواهد شد.
با تابع fopen یک فایل خالی درست میکنیم. پارامتر اول اسم فایل و پارامتر دوم نوع دسترسی تعیین شده برای فایل است. w+ یعنی هم خواندن و هم نوشتن در فایل مجاز است. (اینجا میتوانید راجع به انواع حالت های دسترسی فایل ها بخوانید)
بعد باید با تابع fwrite عکسی که در متغیر image$ ذخیره کردیم را روی فایل بنویسیم. در پارامتر اول فایلی که تازه ساختیم و در پارامتر دوم مقداری که باید در فایل قرار بگیرد، نوشته می شود. که همان متغیر image$ است.
در نهایت باید فایل را با تابع fclose ببندیم تا ذخیره شود.
اگر کد را اجرا کنید و کنار همین فایل scraper.php که کدهای php را در آن نوشتیم نگاهی بیاندازید، عکس دانلود شده را میبینید.
تمام کدهای استفاده شده در این مثال:
<?php
$address = "https://www.digikala.com/product/dkp-3735138";
$ch = curl_init($address);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
$response = curl_exec($ch);
curl_close($ch);
function create_xpath_object($item){
$xmldom = new DOMDocument();
@$xmldom->LoadHTML($item);
$xml_xpath = new DOMXPath($xmldom);
return $xml_xpath;
}
$xpath_object = create_xpath_object($response);
$product_title = $xpath_object->query('//h1');
//title
echo utf8_decode($product_title->item(0)->nodeValue ) . '</br>';
$product_price = $xpath_object->query('//div[contains(@class,"js-price-value")]');
//price
echo utf8_decode($product_price->item(0)->nodeValue) . '</br>';
//image
$img = $xpath_object->query('//img[contains(@class,"c-mini-buy-box__product-info--img")]/@src');
$img_url = $img->item(0)->nodeValue;
echo $img_url . '</br>';
$img_url_clean = strtok($img_url,'?');
//download image
$tmp = explode('/',$img_url_clean);
$filename = end($tmp);
$ch = curl_init($img_url_clean);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,true);
$image = curl_exec($ch);
$http_response = curl_getinfo($ch,CURLINFO_HTTP_CODE);
curl_close($ch);
$file = fopen($filename,'w+');
fwrite($file,$image);
fclose($file);
در این مطلب دیدیم که چطور میتوانیم با استفاده از قابلیت های php خام از یک سایت با وب اسکرپینگ اطلاعات استخراج کنیم. اما وقتی قرار باشد در پروژه های بزرگ تر و با پیچیدگی بیشتر کار کنیم احتمالا استفاده از کتابخانههایی که برای این کار ساخته شده اند مناسب تر باشد. در php کتابخانه goutte مخصوص وب اسکرپینگ ساخته شده است و دردسرهایی استفاده از curl را هم کم میکند.
سعی دارم به زودی این مطلب را با یک مثال از وب اسکرپینگ توسط کتابخانه goutte آپدیت کنم.
سلام لطفا وب اسکرپینگ با goutte رو بذارید ممنون
سلام
حتما. ادامه همین پست در مورد وب اسکرپینگ با goutte مینویسم.