همیشه برای طراحی دیتابیس در پروژه های مختلف یا با حدس و گمان و تحلیل شخصی جلو میرفتم و یا با دیدن و بررسی کردن پروژه های دیگر به یک ساختار برای دیتابیس می رسیدم. استفاده از تجربه دیگران یا تحلیل شخصی اصلا بد نیست اما بهتر از آن، داشتن یک روش و برنامه اصولی برای طراحی دیتابیس است تا موقع شروع یک پروژه دچار سردرگمی نشویم.
در این مطلب درباره یک روش نسبتا خوب که در این کتاب خواندم توضیح دادهام. من از این روش برای طراحی دیتابیس یک نرم افزار کوچک که یک فرم نظرسنجی از خریداران است استفاده کردم و اکثر مثال های من درباره همین نرم افزار است.
مهم است که همه این مراحل را به دقت انجام دهید و چیزی جا نیندازید.
مشخص کردن هدف استفاده از این دیتابیس
اول تعیین کنید از این دیتابیس برای چه نرم افزاری قرار است استفاده کنید. این نرم افزار چه ویژگی هایی دارد؟ قرار است چه کارهایی انجام دهد؟
فهرستی از این موارد تهیه کنید و روی یک کاغذ بنویسید.
مثلا من میخواهم یک نرم افزار نظرخواهی از کاربران برای یک شرکت بنویسم.
فهرست کارهایی که این نرم افزار باید انجام دهد:
- نظر خواهی از کاربران یک وظیفه است که هر ماه در شرکت انجام میگیرد و چند نفر از کارمندان این وظیفه را به عهده میگیرند.
- قرار است یک فرم داشته باشیم. که کاربر یا یکی از کارمندان آن را پر کند.
- در هر فرم تعدادی سوال وجود دارد.
- جواب این سوالات در دیتابیس ثبت خواهد شد.
- مشخصات هر مشتری هم در فرم وجود خواهد داشت.
- اسم کارمندی که نظرخواهی کرده هم در هر نظرسنجی باید ذکر شود.
بعد از این می رویم سراغ کسانی که قرار است از نرم افزار استفاده کنند.
صحبت با کاربر، کارفرما یا هر کسی که قرار است نرم افزار را برای او بنویسیم
در این مرحله باید با فرد یا افرادی که قرار است از نرم افزار استفاده کنند یا این نرم افزار را سفارش دادهاند صحبت کنید.
ببینید چه نیازهایی دارند. چه فیچرهایی برای نرم افزار در نظر گرفته اند. معمولا در حین صحبت با کارفرما حرفهای کلی مطرح میشود. شخصا کمتر دیدهام که قبل از شروع یک پروژه خیلی روی جزییات بین کارفرما و برنامه نویس توافق شود. حرف های کلی مثل “یک فروشگاه اینترنتی میخوام مثل دیجی کالا” یا “یک سایت که ظاهرش قشنگ باشه” نه در طراحی دیتابیس و نه در باقی مراحل توسعه نرم افزار به ما کمکی نمیکند.
-منظور من از جزییات چنین چیزهایی هستند:این فروشگاه اینترنتی قرار است چه محصولاتی داشته باشد؟
-آیا قرار است همه نوع کالایی داشته باشیم. یا اینکه یک سری محصولات محدود فروخته می شود؟
-این محصولات چه ویژگی هایی باید داشته باشند؟
مهم است سوالات دقیق بپرسید و حتما جواب ها را مکتوب کنید. بعدا از جواب این سوالات در طراحی دیتابیس استفاده خواهید کرد.
در مثال سیستم نظرسنجی این چند نمونه از سوالات من بود:
- چه سوالاتی قرار است در نظرسنجی پرسیده شود؟
- آیا سوالات همیشه ثابت می مانند یا به صورت مداوم تغییر میکنند؟
- آیا جواب های تشریحی خواهیم داشت یا همه جواب ها گزینهای است؟
معمولا در فرایند مصاحبه یک سری نکات گفته می شود که به فرایند طراحی دیتابیس کمک می کند.
در حین صحبت هایی که با یکی از کارمندان شرکت درباره نرم افزار نظرسنجی داشتم به این اشاره کرد که هر کدام از کارمندان باید تعداد مشخصی از فرم های نظرسنجی را تکمیل کنند. پس با توجه به این، باید یک قابلیت در نرم افزار داشته باشیم که به هر نفر تعداد مشخصی فرم نظرسنجی محول شود.
تحلیل دیتابیس موجود
اگر از قبل، نرم افزاری برای پروژه مورد نظر وجود داشته باشد، باید آن را تحلیل کنید. ببینید دیتابیساش چه ساختاری داشته. اطلاعات چطور در آن نرم افزار وارد میشده. اگر هم نرم افزاری وجود نداشته، ببینید آیا دیتابیس فیزیکی یا دیجیتال دیگری بوده یا نه. منظورم کاغذهایی است که بایگانی شده یا حتی فایل های اکسلی که اطلاعات در آن ها ذخیره میشده. همه اینها را بررسی کنید. یک نمونه از هر کدام را در یک پوشه نگه دارید تا موقع طراحی دیتابیس از آنها استفاده کنید.
من همین کار را با فرم های نظرسنجی انجام دادم. نمونه ای از فرم ها را برداشتم تا از آن برای طراحی دیتابیس استفاده کنم.
تهیه فهرستی از بخشها یا موضوعات مختلف نرم افزار
مشخص کنید نرم افزاری که قرار است بنویسید چه بخشها یا موضوعاتی دارد. منظورم چیزهایی است که حین توضیح در مورد قابلیتهای برنامه، آنها را به کار می بریم. مثلا وقتی داریم از ویژگیهای نرم افزار حرف میزنیم چنین جملاتی میگوییم:
– “کاربرها بتوانند ثبت نام کنند.” اینجا کاربر می شود یک موضوع.
– کاربرها بتوانند سفارش خودشان را ثبت کنند. اینجا سفارش یک موضوع دیگر خواهد بود.
همینطوری با توجه به صحبت هایی که با کارفرما انجام میدهید یا از تحلیل خواسته های آنها متوجه میشوید موضوعات را استخراج کنید. این موضوعات را در یک لیست بنویسید. این می شود لیست اولیه جدولهای دیتابیس.
برای آنها یک اسم انگلیسی مناسب انتخاب کنید و در یک صفحه آنها را یادداشت کنید.
در مثال سیستم نظرسنجی به این شکل به لیست اولیه جداول رسیدم:
–کاربرها باید بتوانند لیست نظرسنجی های محول شده به خودشان را ببینند. (کاربر و نظرسنجی، users و surveys)
-اطلاعات مشتری باید در فرم نظرسنجی ذکر شود. (customers)
-کاربرها باید بتوانند سوالات را در سیستم تعریف کنند.(questions)
-سه نوع جواب داریم: امتیازی، بله/خیر و چند گزینه ای (answers)
با توجه به این چند ویژگی من به این لیست برای جدولها رسیدم.

تهیه لیستی از فیلدها
در مرحله بعد باید یک فهرست از فیلدهایی که فکر میکنید در دیتابیس این نرم افزار باید باشند بنویسید. فعلا نگران اینکه هر فیلد مربوط به کدام جدول است نباشید. فقط آنها را پشت سر هم بنویسید.
میتوانید از این روش استفاده کنید:
برای تک تک موضوعاتی که در مرحله قبل فهرست کردید ویژگیهایی که فکر میکنید دارند را بنویسید.
مثلا یک موضوع به نام مشتری یا customer داریم. این چند ویژگی با توجه به خواسته های برنامه برای مشتری وجود دارد:
- نام
- نام خانوادگی
- شماره موبایل
- آدرس
- تحصیلات
هر چیزی به ذهنتان رسید در یک لیست بیاورید. این کار را برای همه موضوعات در لیست اولیه جداول انجام دهید.
برای مثالی که خودم روی آن کار میکنم،چنین فهرستی از فیلدها رسیدم:
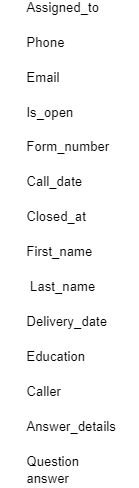
ارتباط دادن فیلدها به جدولها
تا اینجا یک فهرست اولیه از جداول و یک فهرست هم از فیلدها داریم. الان باید ببینیم که هر فیلد مربوط به کدام جدول است. اما قبل از آن باید یک فهرست دوم از جدولها بسازیم.
این بار بدون توجه به لیست اولیهای که از موضوعات نوشتیم تک تک فیلدها را بررسی کنید و اسم موضوعی که به آن مرتبط هستند را در لیست جدیدی بنویسید. این کار را برای این میکنیم تا بدون پیش داوری بر اساس لیست جداول اولیه، بتوانیم تشخیص دهیم که چه جدولهایی برای این فیلدها مناسب هستند.
بعد از این کار اسمهایی که مشابه هستند و مربوط به یک موضوع را حذف کنید و فقط یکی از آنها را بنویسید.
حواستان باشد که اگر دو اسم جدول متفاوت دارید اما ماهیت هر دو یکی است باید یکی از اسم ها را انتخاب کنید و دیگری را حذف کنید. برای مثال ممکن است دو اسم members و users را به عنوان اسم جداول نوشته باشید، اما هر دو مربوط به کاربران سیستم هستند. در این حالت باید تصمیم بگیرید کدام اسم مناسبتر است و از همان استفاده کنید.
بعد از این که اسم جداول را تعیین کردید آنها را به صورت افقی پشت سر هم بنویسید و در زیر هر کدام از جدولها فیلدهای مرتبط را جای بدهید. به این شکل:

تعیین مشخصات فیلدها
الان که فیلدها مشخص شدند باید ویژگی هر کدام را بنویسیم. فیلدها ویژگیهای مختلفی دارند. اما چند تا از آنها مهمتر هستند و باید آنها را حتما تعیین کنیم.
نوع داده Data type
باید مشخص کنیم که در هر فیلد از دیتابیس چه نوع داده ای قرار است ذخیره شود.
این اسامی ممکن است در دیتابیسهای مختلف با همدیگر فرق کند مثلا mysql با sql server در برخی اسامی با همدیگر متفاوتند. با توجه به دیتابیسی که قرار است با آن کار کنید باید مستندات را بررسی کنید.
در mysql این سه نوع داده کلی وجود دارند.
- String
- Numeric
- Date and Time
هر کدام از این موارد انواع داده (data type) زیادی دارند.
-string:
varchar-TEXT-LONGTEXT و …
-numeric:
integer،tinyint،bigint و …
-date and time:
date،datetime،timestamp و…
برای مطالعه در مورد انواع دیگر دیتا در mysql اینجا کلیک کنید.
طول داده
باید تعیین کنیم که حداکثر تعداد کاراکتری که قرار است در این فیلد قرار بگیرد چقدر است.
uniqeness
اگر فیلدی داریم که مقدار آن نباید در رکورد های دیگر تکرار شود این فیلد باید unique در نظر گرفته شود.
برای مثال در جدول users فیلد email باید یک فیلد unique باشد. چون دو کاربر نمی توانند ایمیل یکسان داشته باشند.
Default Value
وقتی این مقدار را تعیین می کنیم که بخواهیم در صورت خالی ماندن فیلد مورد نظر، مقدار از قبل تعیین شده در آن نوشته شود.
null support
اگر یک فیلد می تواند هیچ مقداری نگیرد یا nullable باشد، باید مشخص شود تا در فرایند ورود دیتا به دیتابیس دچار مشکل نشویم. مثلا ممکن است برخی فیلدها که باید از طرف کاربر پر شوند و در دیتابیس قرار بگیرند اختیاری باشند. در چنین مواردی nullable کردن این فیلدها لازم است.
تعیین primary key و foreign key برای جدول ها
در این مرحله باید primary key و foregin key را برای جداول مشخص کنید.
تعریف primary key
هر جدول در دیتابیس باید یک فیلد داشته باشد که به وسیله آن هر رکورد در جدول را بتوان شناسایی کرد. مقدار این فیلد در هر رکورد باید منحصر به فرد باشد. اسم این فیلد را گذاشتهاند primary key.
معمولا مرسوم است که از عنوان ID برای primary key در جداول استفاده میکنند و مقدار آن هم یک عدد است که در هر رکورد جدول متفاوت از بقیه است.

تعریف Foreign key
وقتی قرار باشد بین دو جدول ارتباط (relation) برقرار کنیم، primary key جدول اول به عنوان یک فیلد به جدول دوم اضافه میشود. که در آن جدول به اسم Foreign key شناخته میشود. اگربا ارتباط بین جداول آشنایی ندارید در ادامه در مورد آن توضیح دادهام.
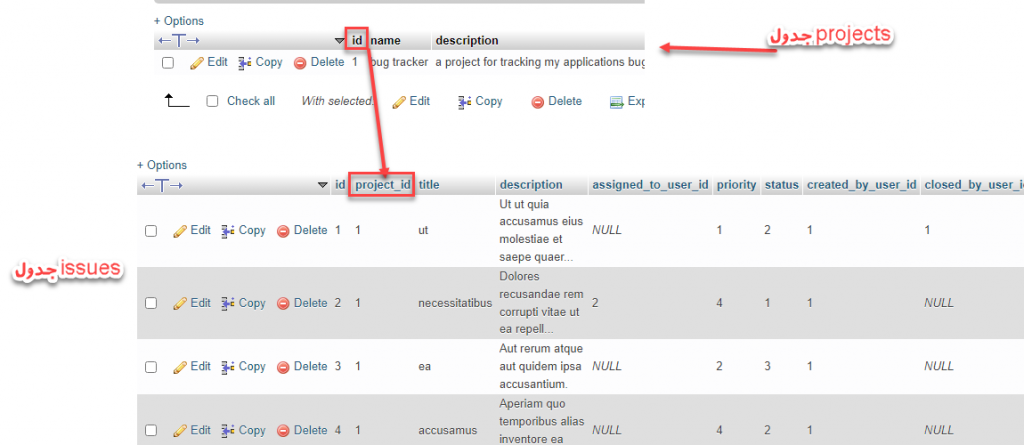
تصویر بالا یک مثال از پروژه باگ ترکر است. ارتباط بین دو جدول projects و issues برقرار شده است. یک فیلد به نام project_id در جدول issues قراردارد. اینطوری می توانیم بفهمیم هر issue مربوط به کدام پروژه است.
پس قبل از اینکه جلوتر برویم به هر کدام از جداول یک فیلد به نام id اضافه کنید.
مشخص کردن ارتباط بین جداول
در این مرحله باید تعیین کنیم کدام جدولها با یکدیگر ارتباط دارند و این ارتباط از چه نوعی است.
در یک دیتابیس، جدول های مختلف می توانند با یکدیگر ارتباط داشته باشند. برای مثال در یک فروشگاه اینترنتی یک جدول به نام users داریم که اطلاعات کاربران در آن ذخیره شده. جدولی هم داریم با نام orders که سفارشات کاربرها در آن ثبت میشود. برای اینکه بفهمیم هر کاربر چه سفارشاتی داشته است، باید بین این دو جدول ارتباط (relation) برقرار کنیم.
هر کدام از سفارشها در یک رکورد جدول orders ذخیره میشوند. هر کاربر هم می تواند چند سفارش داشته باشد. پس ارتباط بین جدول users و حدول orders، از نوع یک به چند یا one-to-many خواهد بود.
به طور کلی سه نوع رابطه یا relation در یک دیتابیس بین جداول می تواند وجود داشته باشد:
- one-to-one یا یک به یک
- one-to-many یا یک به چند
- many-to-many یا چند به چند
ارتباط بین جداول بر اساس فیلد منحصر به فردی است که هر کدام دارند.
مثلا برای اینکه بفهمیم هر رکورد از جدول orders مربوط به کدام رکورد از جدول users است. باید در جدول orders یک فیلد داشته باشیم به نام user_id. در این فیلد id کاربر در جدول users را قرار میدهیم تا بعدا موقع کوئری زدن به دیتابیس راحت بتوانیم سفارشات کاربر را پیدا کنیم.
پیدا کردن نوع ارتباط بین جدول ها
یک جدول مشابه شکل زیر می کشیم تا به ترتیب بررسی کنیم کدام جدول ها با همدیگر ارتباط دارند. من این کار را برای همان سیستم نظرسنجی که طراحی کرده بودم انجام می دهم.
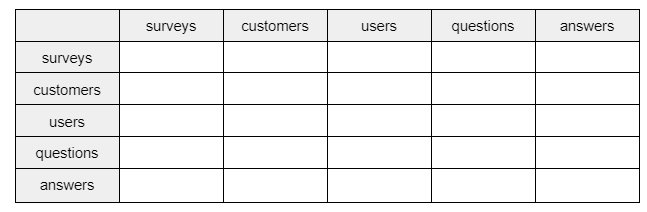
اسم جداول را در سطر و ستون اول مینویسیم. تا با بررسی یک به یک جدول ها با یکدیگر نوع ارتباط بین آنها را در کادر بنویسیم.
برای اینکه راحتتر نوع relation بین جدولها را تشخیص دهید میتوانید چنین سوالی از خودتان بپرسید:
آیا یک رکورد از جدول customers میتواند با یک یا چند رکورد از جدول orders ارتباط داشته باشد؟ چون هر مشتری می تواند چند سفارش بدهد، بله میتواند. پس این جا متوجه میشویم که ارتباط بین این دو جدول از نوع
one-to-many است.
می توانیم از مخفف این relation ها استفاده کنیم:
1:1 یا (one-to-one)
N:1 یا (one-to-many)
M:N یا many-to-many
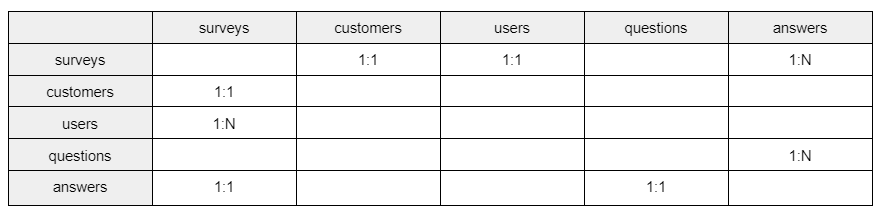
جدول هایی که تشخیص دادم با هم ارتباط دارند را نوشتم. بیایید هر کدام را بررسی کنیم.
-هر بار که قرار است یک نظرسنجی انجام شود باید یک رکورد در جدول surveys ایجاد شود. هر نظرسنجی هم فقط مربوط به یک مشتری است. پس هر رکورد از surveys فقط با یک رکورد از customers میتواند ارتباط داشته باشد. در نتیجه ارتباط این دو جدول one-to-one است.
-تعداد سوالات مشخص است و هر در همه نظر سنجی ها همه سوالات یکسان هستند. پس نیازی نیست بین surveys و جدول questions، ارتباط وجود داشته باشد.
-در این سیستم نظرسنجی، هر کاربر سیستم(user) وظیفه پرکردن فرم نظرسنجی را برعهده دارد و هر کاربر هم در طول زمان چندین فرم را پر میکند، پس ارتباط بین users و surveys از نوع one-to-many است. دقت کنید که users با surveys ارتباط 1:N دارد ولی surveys با users(برعکس قبلی ) ارتباط one-to-one دارد. یعنی هر رکورد surveys فقط با یک رکورد از users ارتباط دارد.
به طور کلی در one-to-many ارتباط از سمت جدول دوم به اولی یک به یک (one-to-one) خواهد بود.
-در جدول answers باید جواب سوالات ثبت شود. در هر رکورد یک جواب قرار می گیرد. پس باید مشخص باشد که هر رکورد از answers مر بوط به کدام رکورد از questions است. پس relation این دو جدول one-to-one است.
از طرفی باید تعیین کنیم هر رکورد از answers مربوط به کدام رکورد از survey است. پس یک ارتباط
one-to-many بین survey و answers وجود دارد. چون هر survey چند جواب خواهد داشت.
پیاده سازی ارتباط بین جدول ها
حالا که مشخص شد هر جدول با چه جدولهایی relation دارد و از چه نوعی هستند، باید این ارتباط ها در جداول را پیاده سازی کنیم.
پیاده سازی ارتباط one-to-one:
برای این کار کافی است primary key جدول اول را در جدول دوم به عنوان foreign key بنویسیم.
در مثال گفتیم که جدول customers با جدول surveys ارتباط one-to-one دارد. پس در جدول surveys یک فیلد اضافه خواهیم کرد به نام customer_id و مقدار آن هم از فیلد id جدول customers اینجا قرار خواهد گرفت.
پیاده سازی ارتباط one-to-many:
برای این کار مانند حالت قبل عمل میکنیم و primary key جدول اول را در جدول دوم به عنوان foreign key مینویسیم.
برای مثال ارتباط بین questions و answers از نوع one-to-many بود پس یک فیلد به نام question_id به جدول answers اضافه میکنیم.
پیاده سازی ارتباط many-to-many:
این حالت با قبلیها فرق میکند. برای این کار نیاز به یک جدول واسط داریم. باید یک جدول بسازیم که حتما دو فیلد داشته باشد این دو فیلد primary key جدول ها هستند.
فرض کنید که دو جدول داریم به نام students و classes. هر رکورد از students با چند رکورد از classes ارتباط دارد و هر رکورد از classes هم با چند رکورد از جدول students در ارتباط است. منطق این قضیه هم واضح است. هر دانشجو می تواند در چندین کلاس باشد و هر کلاس هم می تواند چندین دانشجو داشته باشد.
حالا برای این که چنین ارتباطی را پیاده سازی کنیم باید یک جدول بسازیم که دو فیلد در آن حتما وجود داشته باشد به نام های student_id و class_id تا با کوئری زدن بتوانیم دانشجوهای هر کلاس و همینطور کلاسهایی که هر دانشجو در آن عضو است را پیدا کنیم.
اصلاح فیلدها
با توجه به تمام تغییراتی که از فهرست اولیه جدول ها و فیلدها داشتیم(تعیین primary key،foreign key و relation بین جداول) یکبار دیگر باید جدول ها را به همراه فیلدهای اضافه یا کم شده بنویسیم.

رسم جداول با استفاده از ابزار دیاگرام سازی
اینکه فهرستی از جداول به همراه فیلدها و همینطور relation بین جداول داشته باشیم برای شروع توسعه نرم افزار کفایت میکند اما در پروژههای گروهی برای به اشتراک گذاری ساختار یا به طور کلی برای نمایش بهتر دیتابیس طراحی شده نیاز به رسم این ساختار داریم.
معمولا برای رسم ساختار یک دیتابیس از دیاگرامها استفاده می کنند. به این شکل دیدن جداول، فیلدها و ارتباط بین جداول راحتتر است. ابزارهای آنلاین و آفلاین زیادی برای این کار وجود دارد. من از این سایت برای رسم دیاگرام دیتابیس استفاده میکنم.
کار با آن ساده است و خروجی های مختلف هم از آن میتوانید بگیرید.
بعد از ورود به سایت و کلیک روی گزینه Go to App، وارد صفحهای می شوید که در سمت چپ آن به صورت نوشتاری و کد جدول ها را تعریف کنید تا در سمت راست صفحه، دیاگرام نمایش داده شود.
در سمت چپ صفحه جدول ها را به همراه فیلدها به این شکل تعریف کنید:
Table customers {
id int [pk]
first_name varchar
last_name varchar
phone varchar
education varchar
}کدهایی که اینجا نوشتیم با یک زبان ساده به نام DBML است که برای طراحی ساختار دیتابیس ساخته شده.
هر جدول با کلمه Table شروع میشود و بعد از آن اسم جدول میآید. فیلدهای جدول هم بین دو علامت {} قرار میگیرند.
در هر خط یک فیلد نوشته میشود و با یک فاصله data type آن فیلد را هم میتوانیم بنویسیم. برای مشخص کردن primary key هم از عبار [pk] استفاده می کنیم تا در جدول رسم شده به شکل بولد نمایش داده شود.
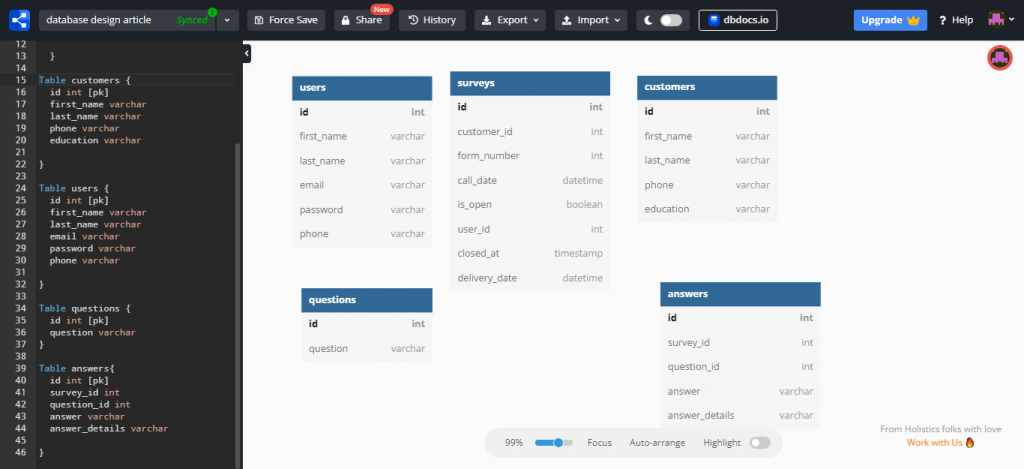
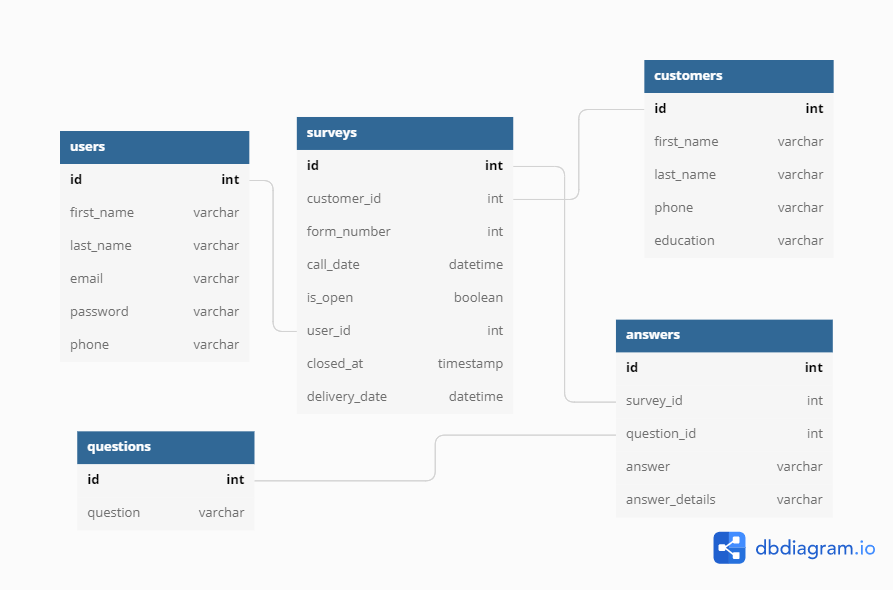
با کشیدن ماوس از یک فیلد به فیلد دیگر((از primary key به foreign key)) بین دو جدول میتوانید ارتباط
دو جدول را نمایش دهید.
جمع بندی
-روشی که در این مطلب برای طراحی دیتابیس استفاده کردم برا اساس کتاب Database Design for Mere Mortals بود. تجربه شخصی من از استفاده از این روش مثبت بود و طراحی دیتابیس یکی دو برنامهبعد از یادگیری این روش راحت تر شده. چون الان یک روش مرحله به مرحله مشخص دارم که طبق آن دیتابیس را طراحی می کنم.
-به نظرم مهمترین بخش طراحی دیتابیس تعیین هدف استفاده از دیتابیس و صحبت با کارفرما برای تعیین نیازهای پروژه است. اگر این دو مرحله را با دقت و حوصله انجام بدهیم، ادامه کار برای ما روشن راحتتر است.
سلام خیلی ممنونم از اینکه مختصر و مفید نوشته بودید.
سلامت باشید
ممنون👌
شیوه کاربردی بود مرسی.